
No final do mês passado, a Imogestin procedeu à abertura de inscrições online para habitações na centralidade do Zango 5. O processo iniciou com inúmeros problemas de acesso ao portal, possivelmente pelo excesso de acessos em simultâneo de internautas interessados em fazer a inscrição, até se considerar solucionado. Passados 3 dias, 115 mil internautas conseguiram fazer a inscrição. Não deveria o processo ser infalível? Sim, mas não foi.
Mas antes: segurança#
No ano passado, falei da importância em proteger o acesso remoto dum servidor Windows, pois ao contrário do Linux, o Windows Server vem com muitas portas abertas por defeito, essenciais para o funcionamento em uma rede interna, mas desnecessárias e potencialmente perigosas se ignoradas e/ou se não forem monitorizadas.
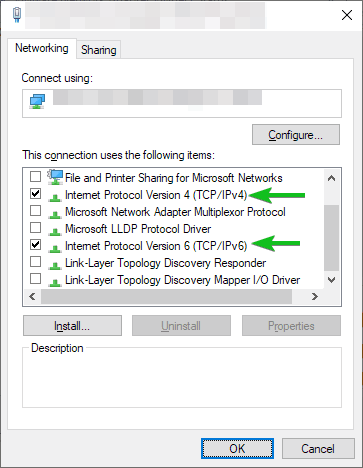
As portas 139/NetBIOS e 135/RPC podem dar acesso a ficheiros do sistema, mas se o servidor vai estar ligado directamente a internet, minimiza o risco de exposição, desactivando tudo nas propriedades da interface de rede excepto Internet Protocol Version 4 (TCP/IPv4) e Internet Protocol Version 6 (TCP/IPv6) se necessário. No entanto, um firewall é sempre a melhor opção e melhor protecção.
O ínicio: servidor#
Durante as primeiras horas, o site teve dificuldade para servir milhares de pedidos. Sendo o servidor web IIS, talvez por necessidade (para interagir com o Microsoft SQL) e não por opção, o site pareceu-me um bocado lento mesmo antes da abundância de pedidos. O que vem a cabeça como primeira causa é falta de memória RAM: o servidor tinha apenas memória suficiente para o funcionamento de baixo tráfego no dia-a-dia e quando deparado com a avalanche, começou a desacelerar e até mesmo, a não servir internautas.
Alternativa: Se o backend não depende de ASP.net, o servidor web fica melhor servido com Linux e Litespeed.
Horas mais tarde, o regresso… implacável?#
Durante a manhã do mesmo dia, a situação ainda andava aos sobressaltos e presumo que por essa altura foram adicionados mais dois servidores, fazendo um total de três em modo round-robin com um TTL (Time to Live) de 1 minuto:
C:\>nslookup -debug www.imocandidaturas.co.ao
...
QUESTIONS:
www.imocandidaturas.co.ao, type = A, class = IN
ANSWERS:
-> www.imocandidaturas.co.ao
internet address = 94.46.175.28
ttl = 60 (60 secs)
-> www.imocandidaturas.co.ao
internet address = 94.46.21.116
ttl = 60 (60 secs)
-> www.imocandidaturas.co.ao
internet address = 94.46.21.117
ttl = 60 (60 secs)
...
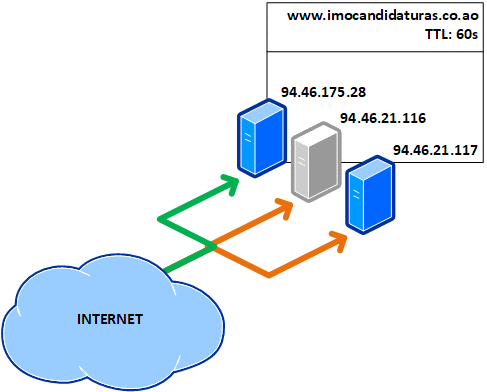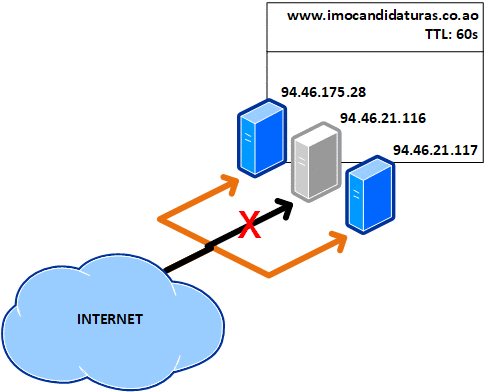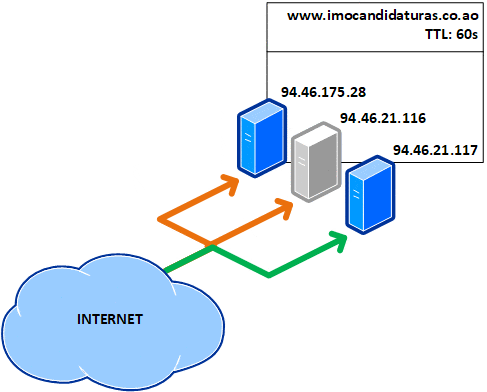
Isto quer dizer que, a cada minuto, o registo DNS do portal expira no cache local e mesmo tem de ser consultado novamente nos servidores de nomes, também conhecidos como name servers ou NS, recebendo outro IP, como ilustrado abaixo com a cor verde:
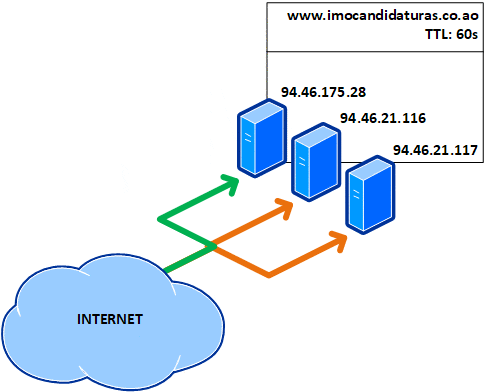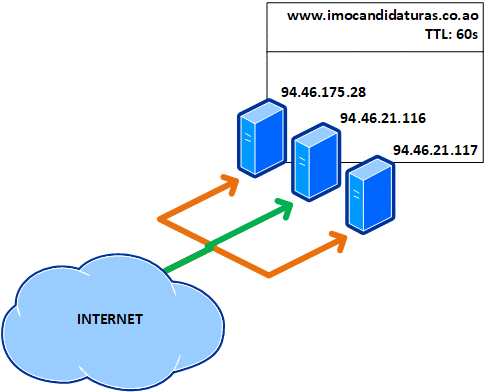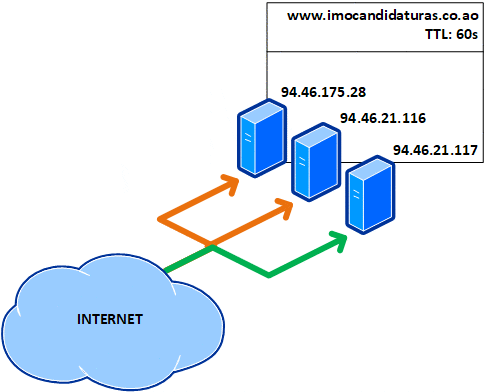
Não tenho nada contra esta ser uma alternativa urgente a curto prazo e assim parece que o foi, mas para motivos educacionais, vejamos o que acontece se implementado a longo prazo:
Uma TTL de 1 minuto aumenta a latência ao aceder um site e a dependência dos name servers. Isto faz com que as consultas aos registos ocorram com maior frequência. Este valor geralmente é usado quando há mudanças de registos (como a migração do serviço para um novo IP). Isto infelizmente não protege contra falhas, porque se um dos três servidores fica (e deve ter ficado) inoperante, todas os internautas que acederam ao mesmo ficam presos a ele durante 60 segundos até o registo expirar:
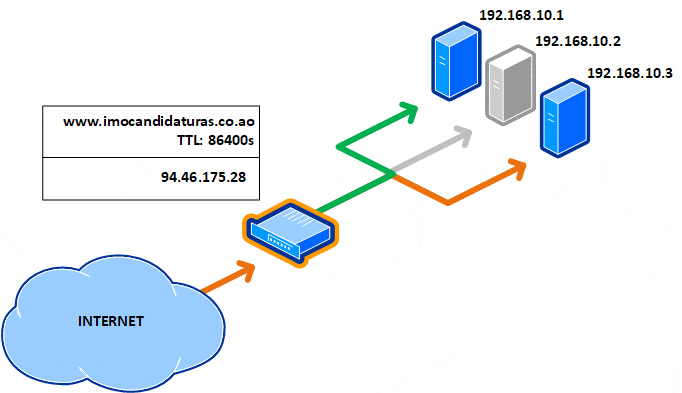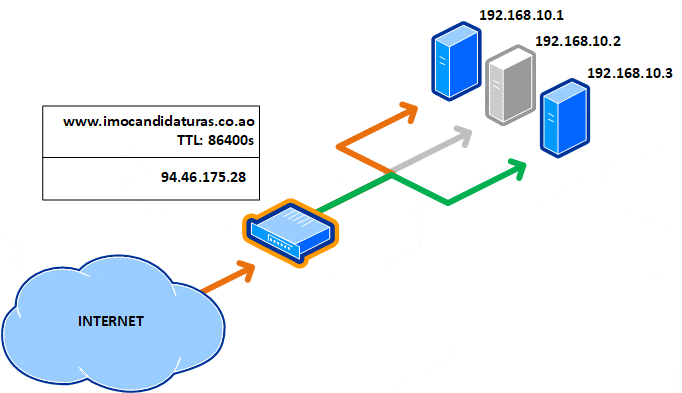
Existe uma solução melhor? Para serviços críticos e que necessitam estar sempre acessíveis, o essencial é ter um balanceador de carga no front end, como o Kemp ou open-source como o HAProxy. Dessa forma, somente irá ter um registo DNS e não necessita ter um TTL baixo, sendo o recomendável 24 horas (86,400 segundos).
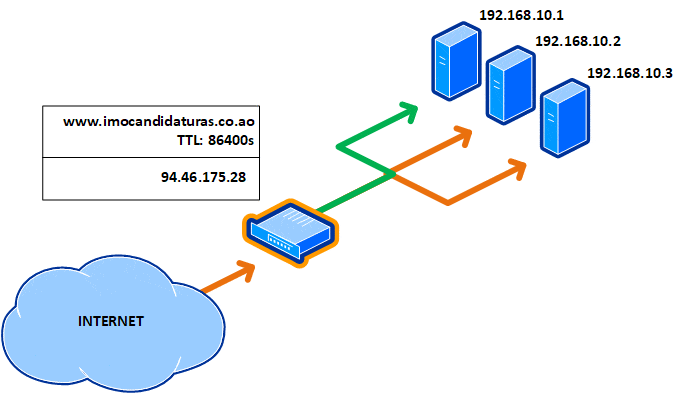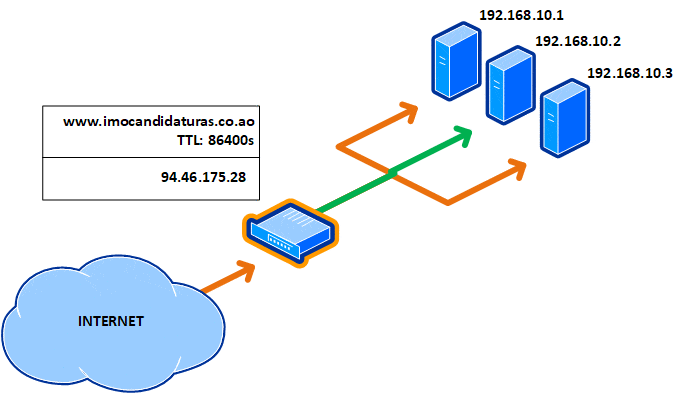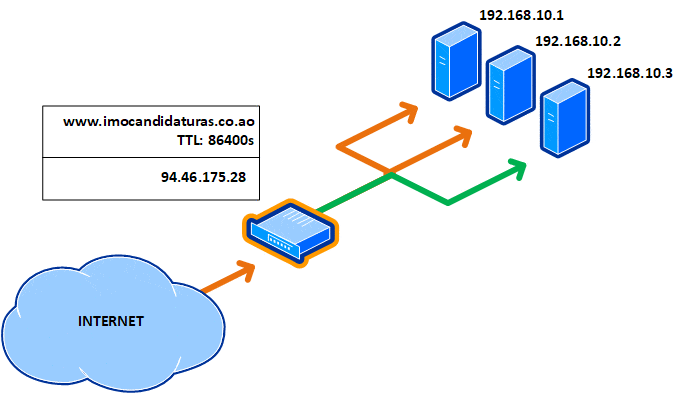
No caso de falha de um servidor, não ficas a jogar roleta russa com o round-robin. O balanceador faz a monitorização dos servidores no back-end, que em caso de falha, retira-o do grupo de balanceamento, sendo a operação totalmente invisível para o internauta.
A palavra final que deixo para toda implementação é antecipação. Existem ferramentas como o Loader para criar testes de stress enviando milhares de ligações simultâneas, permitindo assim, um teste mais exaustivo antes do grande lançamento.
Prepara-te atempadamente para eventuais picos, principalmente se tens conhecimento adiantado que o número de visitas vai ser muito maior que o normal, e saíres como um exemplo, não como um motivo de frustração.